Автор: +Алексей Раскин
Давайте предположим, что вы решаете задачу о том, сколько электроэнергии будет потреблять город Кемерово ближайшие 20 лет. (Ссылка на модель)
Итак. Как выглядит процесс моделирования? Существенно упрощенный, но вполне реальный. Мы пройдем по основным этапам моделирования и в конце у нас должна появиться модель. Простая, но рабочая.
Давайте признаемся: прогнозировать потребление электроэнергии само по себе очень сложно. Нет никаких зацепок. Мы можем прогнозировать другие, более понятные нам величины от которых зависит потребление, но не можем прогнозировать саму по себе совершенно неясную нам величину “потребление электроэнергии”.
Таким образом, нам нужно выделить факторы (это очень важное слово, запоминаем его), от которых будет зависеть потребление. Чаще всего (за редким исключением тех случаев, когда в голове у аналитика есть точный план модели и точное понимание всех факторов) процесс построен примерно следующим образом:
Шаг 1. Начинать всегда надо с самого начала.
Начать надо хоть с какой-либо исходной информации. Например, у каждого города есть тот или иной генеральный план, у Кемерова - вот тут.
Из раздела “Электроснабжение” мы узнаем, что:
- в 2012 году потребление было 3070 млн. кВтч.
- По прогнозу электропотребление в 2022 году составит 4100 млн. кВт/ч
- По прогнозу электропотребление в 2032 году составит 5100 млн. кВтч.
Нам нужен собственный прогноз, но на первом этапе мы можем сделать вид, что нас вполне устраивает прогноз по генеральному плану. Поэтому пока поставим цифры в соответствующие года. А между ними (в 2013-2021 и 2023-2031 годах) сделаем формулу постепенного роста. Она довольно простая.
Шаг 2. Эх, понеслась!
Однако, нас такой прогноз все-таки не устраивает по многим причинам:
- Мы не понимаем исходных предположений для прогноза: какое прогнозируется население, какие предположения относительно электрефикации районов и т.д.
- Мы не понимаем, как те или иные факторы влияют на прогноз. Например, можем ли мы, глядя на лист модели “Шаг 1.” сказать, сколько электроэнергии будет потребляться, если в Кемерово случится бейби-бум и население существенно увеличится? Не можем. А ведь основная задача модели - это просчитывать разные варианты развития событий. Значит, наша модель (состоящая из одной строчки) плохая.
Итак, разбиваем на факторы и строим свой прогноз. От чего зависит потребление электроэнергии? Предположим, что оно зависит от населения. Берем население в 2012 году, берем потребление электроэнергии в 2012 году и находим, сколько электроэнергии потребляет один житель. Дальнейший наш прогноз прост: мы считаем, что это количество электроэнергии на жителя не меняется и умножаем прогноз населения (взятый из того же генплана) на эту величины. См. лист “Шаг 2”.
Шаг 3. Что-то здесь не так.
Прогноз, очевидно, плохой. И вот почему. У нас получилось, что в среднем один человек потребляет почти 490 кВтч в месяц. Домашнее задание: спросите у родителей, сколько они платят за электроэнергию и сколько по показаниям счетчика вы потребляете электроэнергии в месяц на человека. Уверяю, будет значительно меньше. Примерно, в 10 раз. Почему же у нас 490? Да потому что мы разделили на население все потребление, включая фабрики, совхозы, заводы, водоканал, трамвайное сообщение… В общем, очевидно, что потребление электроэнергии состоит из 2 частей: население и промышленность. И их нужно прогнозировать отдельно. Поехали! Берем среднее потребление электроэнергии на человека: 60 кВтч в месяц или 720 кВтч в год, умножаем численность населения и получаем потребление э/э насления. Остальное - промышленность.
Считаем стартовые цифры по 2012 году, а остальное прогнозируем: население немного растет в соответствии с прогнозом генплана, а промышленность остается как есть (об этом немного позже).
Шаг 4. Дополнительные факторы.
Что теперь мы можем уточнить или поставить под сомнение?
- Потребление промышленностью. Пока у нас крайне консервативный прогноз. Пожалуй даже слишком консервативный. Но мы строим упрощенную модель, поэтому здесь я не буду рассматривать этот вопрос детально. Я лишь сделаю заготовку, которая позволяет увеличивать потребление э/э промышленностью, если у вас есть информация о строительстве и потреблении новых заводов. Вдруг есть?
- Неизменность потребления электроэнергии одним человеком. Это не так. По крайней мере, сейчас активно внедряются энергосберегающие лампочки, которые будут потреблять в 10 раз меньше текущих обычных лампочек. Поэтому, в модели мы разобьем потребление человека на две категории: потребление э/э на освещение и потребление э/э на прочие нужды в соотношении примерно 30 к 70. Оно где-то так и есть. Теперь мы можем посмотреть, что будет, если в течение нескольких лет мы будем плавно заменять старые лампочки на новые. Обратите внимание, что вертикальная ось не с нуля. Так лучше видно различие в прогнозах.
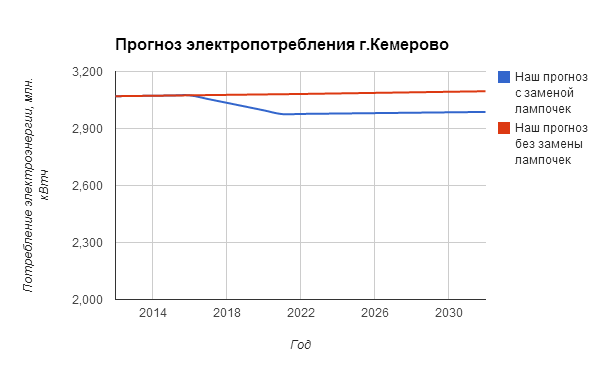
Шаг 5. Может уже хватит?
Предположим, что нас устроивает глубина нашего прогноза и все факторы, которые мы хотим влияение которых мы хотим учесть у нас в модели есть. Что осталось? Сравним наш прогноз с прогнозом по генплану. Различия очень большие. У нас - постепенное снижение из-за стабильного потребления промышленностью и снижением потребления за счет энергоэффективных лампочек. В генплане - существенный рост. Теперь можно пойти в администрацию и попытаться выяснить, почему они столь оптимистично смотрят на рост потребления? :) и сравнить их предположения пофакторно с нашими. Вероятнее всего, мы не учли рост потребления промышленностью, а они забыли о том, что потребление населением будет немного снижаться.

Резюме. Что нам дала хорошая модель?
1. Возможность сравнивать свои вычисления с другими мнениями на этот счет. Когда мы видим только итоговую цифру прогноза мы никогда не поймем в чем различия. С нашей моделью на листе “Шаг. 4” можно пойти в Администрацию и сравнивать, но если бы мы пошли в Администрацию с моделью состоящей из одной строчки (наподобие той, которая на листе “Шаг 1.” Мы бы никогда не поняли, где различия в нашем виденьи будущего города Кемерово.
2. Возможность “прогонять разные сценарии”. А что будет, если построим и запустим завод? А что будет, если население увеличится? а что будет если лампочки новые поставим? А что будет, если потребление на одного человека снизится, потому что мы введем строгий запрет на посудомоечные и стиральным машины? В действительности, это очень важно. Во-первых, так как будущее невозможно предсказать точно, всех интересует некоторый возможный диапазон развития событий. Мы понимаем, что угадать потребление электроэнергии в 2025 году невозможно, но мы можем указать некий диапазон (в разных сценариях), в котором будет лежать искомая величина. А во-вторых, таким образом мы можем оценивать эффект от различных событий на ситуацию в целом. А хватит ли пропускных способностей сетей, если мы введем новый завод? А не придется ли останавливать электростанцию из-за наших многострадальных лампочек?
И совсем напоследок. Полезные мысли.
Нужно понимать, что опытный аналитик проводит большую часть таких операций в голове (особенно, если он хорошо понимает предметную область). В крайнем случае, общая архитектура модели (в том числе, анализируемые факторы) просто фиксируются на листочке бумаги и потом сразу делается модель (как на листе “Шаг 4.”, без промежуточных вариантов). Ну а если сразу сложно или задача носит исследовательский характер, то можно и так - итерациями и уточнениями. В 9 случаях из 10 будет что-то среднее между двумя этими подходами.
Почему используются электронные таблицы и какие именно?
Сразу оговоримся, так как большую часть времени работал с Excel, то писать буду именно о нем, хотя электронных таблиц на свете много. Самые известные: Excel, Calc, Number, Google Spreadsheets… Однако, мне неизвестны случаи, когда в серьезном коммерческом проекте в качестве электронных таблиц использовали не Excel (они наверняка есть, но за 6 лет работы с разными компаниями ни одного не видел). Причин тут две:
1) Распространненость. Когда у всех установлен Excel, все используют Excel, вам присылают файлы в Excel, а в договорах прописывают необходимость “предоставить расчеты в формате Excel”, вам ничего не остается делать. Вы используете Excel.
2) Качество продукта. Как бы ни было модно ругать Microsoft (иногда заслуженно, иногда - нет), но Microsoft Office остается, пожалуй, одним из лучших офисных пакетов. А Excel в его составе демонстрирует и удобство и высокую производительность (значительно более высокую, чем, например, LibreOffice Calc).
Тем не менее, в данном материале мы использовали Google Spreadsheet: у нас простая модель, которую надо показать сразу большому количеству человек. Это тот случай, когда Google Spreadsheet - в самый раз. Заодно это будет хорошей иллюстрацией того, что как бы вы ни любили один продукт, иногда более разумно “переключаться” и использовать альтернативы.
Никогда не слушайте тех, кто знает "самую лучшую программу на все случаи в жизни". Всегда нужно подбирать подходящий инструмент. В нашем случае удобен продукт Google, но если бы я сел делать большую и сложную модель, я бы выбрал - Excel. А если бы я знал, что мои коллеги работают под ОС Linux, мне следовало бы выбрать Calc.
Почему же для моделирования используется именно табличный редактор? Если коротко, то он хорошо подходит для проведения прозрачного и несложного с математической точки зрения анализа. В случаях, если вам нужны сложные вычисления (дифференциальные уравнения, интегралы, пределы или какие-то сложные алгоритмы), если все это должно происходить в режим реального времени, то конечно Excel и его собратья не помогут. Однако, есть целый ряд значительно более простых задач, для которых использовать громоздкие математические пакеты - это как стрелять из пушки по воробьям. Простота и прозрачность моделей, сделанных в Excel, дает следующие преимущества:
- Низкий порог вхождения. Вы можете показать свою модель человеку без специального математического или программистокого образования (например, экономисту) и он с высокой долей вероятности сможет разобраться с моделью.
- Скорость разработки. Простые правила позволяют вносить изменения или приделывать какие-то новые элементы к модели в очень сжатые сроки.
- Гибкость и возможность слияния моделей. Вы можете легко взять одну модель и “залинковать” (поставить ссылки) на другую модель, скопировать листы из одной модели в другую и т.д.
- Чуть более сложный пункт, но важный. Excel одновременно может являться (а может и не являться) и хранилищем данных, и инструментом их обработки. Если у вас не очень много данных, то вы храните их в файле Excel и там же обрабатываете. А если данных очень много, то храните их в любой базе данных и импортируете их в Excel по мере надобности. Таким образом, если данных мало, а человек не обладает необходимыми знаниями в области баз данных и языка SQL, то использование Excel как хранилища данных существенно упрощает жизнь: на одном листе информация, а на соседнем - расчет на ее основе.
У каждого плюса есть свой минус. Так всегда и везде.
- Низкий порог вхождения порождает больше количество файлов и моделей низкого качества, сделанные неквалифицированным людьми.
- Высокая скорость разработки создает у руководства иллюзию того, что все можно сделать очень быстро (почти мгновенно). К моделированию в Excel не относятся так, как, например, к обычному программированию, хотя суть работы одна и подходы к ней примерно такие же.
- Большое количество файлов, ссылающихся друг на друга, обновляемые и меняющиеся версии. Довольно сложно держать это в голове, а нормальной системы контроля версий для файлов типа Excel не существует (в отличие от аналогичных систем для обычных языков программирования).
- Беспорядочное хранение информации в файлах Excel чревато потерей данных, несвоевременным обновлением, ошибками в данных и их противоречивостью.
И напоследок пару полезных советов:
- Старайтесь указывать источники данных. Это очень важно. Без них модель по большому счету не имеет смысла.
- Год, по которому есть фактические данные и от которого мы отталкиваемся в расчетах, обычно называется базовым годом. В нашей модели это 2012 год.
- Старайтесь в модели выделять форматированием (курсивом, жирным шрифтом, неяркими цветами и/или отступами) уровни факторов. Например, итоговая цифра - жирным, следующие ее составляющие - обычным шрифтом, еще более мелкий уровень - курсивом. Или отступами.
- Порой, даже супер-мега-глобальные модели можно проверять “личным опытом”. Это то, что мы сделали, обратив внимание на очень высокий уровень потребления одним человеком. Бытовое знание о том, сколько вы платите за электроэнергию и сколько потребляете, помогает обнаружить ошибку в, казалось бы, таком глобальном вопросе, как потребление целого города.
Комментариев нет:
Отправить комментарий